- Management Commitment
- Purpose
- Objectives
- Scope
- Definitions
- Roles and Responsibilities
- Classifications
- Sensitivity Levels
- Coordination Among Entities
- Prioritization
- Levels of Authority
- Performance Measures
Why do you need an incident response capability?
Even the best security programs have gaps. It’s critical to respond when security breaches occur. Developing an incident response capability can reduce the impact of an incident. It can also help you document evidence and meet legal requirements.
The US code of federal regulations contains many references to incident management capabilities. Several of them mandate non-federal organizations to document and report incidents.
- Health Insurance Portability and Accountability Act (HIPAA)
- Requires an incident response plan for covered entities and business associates
- Requires an incident response plan to handle controlled unclassified information.
- Requires certain entities in the energy sector to have an incident response plan.
Authoritative sources on incident response capabilities
We found several sources that discuss this subject in great detail:
- National Institute of Standards and Technology (NIST)
- Special Publication (SP) 800-61 Rev2
- Special Publication (SP) 800-53 Rev5
- Defining Incident Management Processes for CSIRTs
- CERT® Resilience Management Model, Version 1.2
- Good Practice Guide for Incident Management
- CSIRT Case Classification (Example for Enterprise CSIRT)
Components of Incident Response Policy
This blog is going to focus on the creation of an incident response policy. Policies often establish a set of objectives for the organization. In a separate blog, we discuss creating an incident response plan. The plan details how the organization implements their policy.
Both NIST publications cited above contain guidance for drafting an incident response policy. The other publications are helpful for documenting these components.

The policy elements cited in NIST SP 800-61 Rev 2 go well beyond the requirements listed in NIST SP 800-53 Rev 5. Each organization will tailor their own elements into their policy.
For our template, we opted to incorporate those headings with bold font in the venn diagram. We cover handoff & escalation points in our incident response plan. We tailored out the organizational structure as it is specific to each organization.
Management Commitment
Management should understand and approve all policies. By signing a policy, management commits to the content contained within the policy.
We wrote a short statement summarizing the commitment from management:
Effective incident response is essential to ensuring the fulfillment of our mission. We recognize that disruptive events have the potential to impact our business operations. If we cannot prevent all risks, we must remain prepared to manage their consequences.
We commit to having a functional incident response capability. This capability includes detecting, containing, and recovering from security incidents. To meet these goals, we have identified the roles and responsibilities required. We have documented the prioritization of incidents based on their criticality. We will measure our performance and strive to improve over time.
A more detailed incident response plan supplements this policy.
_______________________
Authorized Organization Official
Purpose
The purpose section of a policy should describe what the policy sets out to do. If you’re struggling to write the purpose section, start with the objectives section. Once you've written our the objectives, look to summarize them as the purpose of the policy.
Our purpose statement reads:
The purpose of our incident management capability is to establish processes. These processes govern how we identify and analyze events to detect incidents. They also govern how we categorize and prioritize incidents. These processes help us determine and document an appropriate organizational response.
Objectives
When writing our objectives, we wanted traceability to the incident response plan. Our objectives stem from the mission statements for our five main workflows.
For example, the prepare workflow includes two mission statements:

We combined these into a single statement as our first goal. The others come from the workflows for protection, detection, triage, and response.
The objectives section of the policy reads:
We recognize the need to establish a multilayered approach to protect critical assets. We have defined organizational and technical approaches to manage computer security incidents. The key requirements and objectives include:
To create and improve a formalized cybersecurity incident response team (CSIRT) capability.
- To protect and secure critical data and the computing infrastructure
- in response to current risk, threats, attacks
- in response to proposed improvements
- based on a predetermined schedule
- while handling information within the appropriate security context
- To identify unusual activity that might compromise the mission
- within defined time constraints
- while handling information within the appropriate security context
- To sort event information and assign it to appropriate personnel
- within defined time constraints
- while handling information within the appropriate security context
- while documenting information in an appropriate manner
- To resolve events and incidents
- within defined time constraints
- according to established policy, procedures, and quality requirements
Scope of Applicability
Scope refers to the parts of your organization that this policy applies to. Scope can include organizations, individuals, technology assets, or facilities. We drafted our policy with the following scope:
The scope includes employees with access to organizational data and systems.
Definitions
A policy is a great place to define terms.
Here are some of the terms we defined in our policy:
- Breach - unauthorized use or disclosure of protected health information.
- Business Impact - the combined functional and informational impact of an incident.
- Computer Security Incident - a violation of policies or security practices.
- CSIRT (Cybersecurity Incident Response Team) - the team performing the incident response capability.
- Event - occurrences that have the potential to disrupt operations.
- Event Triage - The process of categorizing, correlating, and prioritizing events.
- Functional Impact - degree of negative impact an incident has on systems and users.
- Incident - see Computer Security Incident
- Informational Impact - categorization of the impact to sensitive information
Technical Information - data associated with incidents. May include hostnames, IP addresses, malware, precursors and indicators, and vulnerabilities exploited.
Roles and Responsibilities
The Good Practice Guide for Incident Management details mandatory and optional roles. These roles serve to group together tasks performed within the incident management function. For larger organizations, many individuals or teams may fill a role. For smaller organizations, a single individual may fill many roles.
Here are the roles and responsibilities we defined:

Classifications
The Forum of Incident Response and Security Teams (FIRST) manages a list of categories. There are a couple reasons organizations should classify incidents. First, certain categories may warrant higher sensitivities and more restricted communications. Second, having discrete categories allows for more detailed analysis of performance.
Here are the categories we used in our policy:

Sensitivity Levels
The FIRST incident categories relate to a sensitivity classification table. Here is how we introduced the sensitivity matrix in our policy:
Incident managers apply the “need to know” when communicating case details. The sensitivity matrix classifies cases according to sensitivity levels.

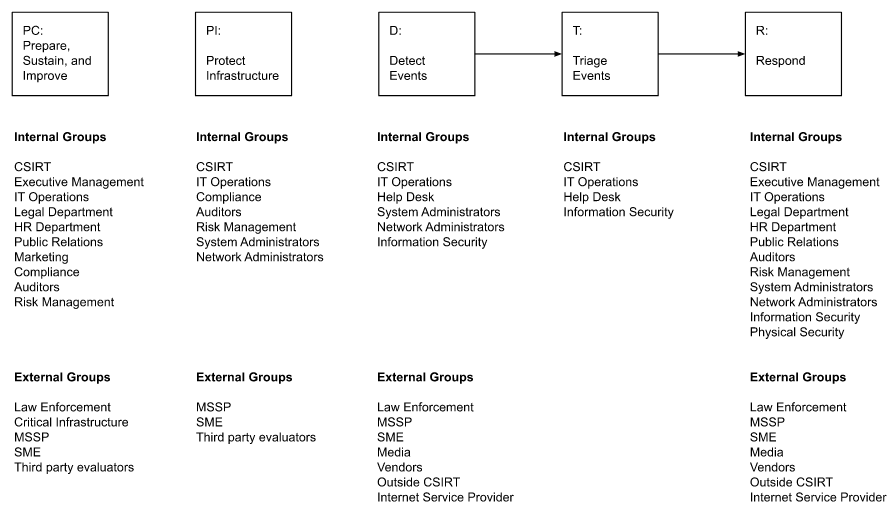
Coordination Among Entities
The policy should document approved contacts at outside organizations. Here is how our policy address coordination among entities:
The legal department has approved sharing specific information with external organizations.

Several internal departments coordinate through the incident response process. Below is a table of key internal contacts involved in incident response:

Our incident Response Plan documents each group's involvement throughout the process.
Prioritization
NIST SP 800-61 discusses three factors relevant to prioritizing incidents. These factors include the functional and information impacts and the recoverability effort. Here is our formatting of the prioritization section of our policy:
The functional and information impacts as well as the recoverability effort determine prioritization. The following tables detail the categories of each factor:
Functional Impact of the Incident - categorizes the negative impact to business functions.

Information Impact of the Incident - categorizes the effect on the organization's data. The information impact categories are not exclusive (except for "none").

Recoverability Effort of the Incident - categorizes the resources required to recover.

We calculate Business Impact by combining the functional and information impacts. We determine criticality as a function of the business impact and recoverability effort. We assign criticality levels using the CSIRT criticality matrix:

Levels of Authority
The policy should give authority to confiscate equipment and to track activities. Having only procedures that list these specific functions is insufficient . Here is how we addressed this section in our policy template:
Staff operating within CSIRT roles have the authority to track suspicious activity. Some roles also have the authority to confiscate or disconnect equipment.

Compliance
There are two common compliance requirements for reporting incidents. We have listed both in our sample policy and detailed the requirements for each.
To comply with the HIPAA Breach Notification Requirements , following a breach of unsecured protected health information, we commit to:
- Provide written notice to affected individuals within 60 days
- Send notices via email for individuals that agreed to this form of communication. Others will receive notices via first-class mail.
- Include a brief description of the breach and the types of information involved. Outline the steps affected individuals should take to protect themselves from potential harm. Identify steps we are taking to investigate, mitigate harm, and prevent further breaches.
- If our contact information for more than 10 individuals is out of date, then we will post a notice. The notice will live on the homepage of our website for at least 90 days. The notice will include a toll-free phone number. We will confirm the involvement of affected individuals who contact us.
- We will notify media outlets when a breach affects 500 residents or more of a State or jurisdiction. We will make this notice within 60 days of the discovery of the breach.
- We will submit anotification to the US. Department of Health and Human Services Office for Civil Rightsfor any breach. We will submit notifications within 60 days when the breach affects 500 individuals. We will report all other breaches within 60 days of the calendar year of the breach.
To adhere to the DoD Cyber Incident Reporting requirements, we commit to:
- Acquirea DoD-approved medium assurance certificate to report cyber incidents.
- Identify compromised systems and data when we discover a cyber incident. Verify if it affects a covered information systems or the covered defense information.
- Analyze information systems that were part of the incident and others on the network. Verify unauthorized access to systems as a result of the incident.
- Identify compromised covered defense information or impaired abilities to provide critical support.
- Report the cyber incident to DoD athttps://dibnet.dod.milwithin 72 hours.
- Treat the cyber incident report as information created by or for DoD
- Isolate malicious software and submit it toDoD Cyber Crime Center (DC3). Follow instructions provided by DC3 or the Contracting Officer.
- Protect images of all known affected systems, packet capture and monitoring data. Preserve this data for at least 90 days from the submission of the cyber incident report.
- Provide DoD with access to information or equipment as requested to conduct analysis.
- Provide all damage assessment information to the Contracting Officer upon request.
Performance Measures
Incident data has the potential to provide several measures of success. Here is how we addressed this section in our policy:
We collect and store actionable incident data to provide measures of performance. These metrics include:
- Number of Incidents Handled - measures the relative amount of work performed. We categorize incidents using the CSIRT incident categories.
- Time per Incident - for each incident, we measure the time in several ways:
- Total amount of labor spent working on the incident
- Time from incident discovery to impact assessment and through each stage of handling
- Initial response time
- Time to report the incident to management and appropriate external entities
- Objective Assessment - We analyze the response to determine its effectiveness. The following are examples of objective incident assessments:
- Review of incident documentation for adherence to established incident response policies and procedures.
- Identify recorded precursors and indicators to determine detection and logging effectiveness.
- Determining if the damage occurred before incident detection.
- Verify if we identified the actual cause of the incident. Identify the vector of attack and vulnerabilities exploited. Identify the characteristics of the targeted or victimized systems.
- Determining if the incident is a recurrence of a previous incident.
- Calculating the estimated monetary damage from the incident. Include information and critical business processes affected by the incident.
- Measuring the difference between the initial impact assessment and the final impact assessment.
- Identifying which measures, if any, could have prevented the incident.
- Subjective Assessment - Team members assess their own performance and the team's performance. We request input from the resource owner on their satisfaction with the outcome.
