and look for a transition kernel that will converge to this equilibrium distribution.
Island hopping¶
We first provide an example to show the mechanics of the Metropolis algorithm concretely, then explore why it works.
Kruschke’s book begins with a fun example of a politician visiting a chain of islands to canvas support - being callow, the politician uses a simple rule to determine which island to visit next. Each day, the politician chooses a neighboring island and compares the populations there with the population of the current island. If the neighboring island has a larger population, the politician goes over. If the neighboring island has a smaller population, then the politician visits with probability \(p = p_\text / p_\text\) ; otherwise the politician stays on the same island. After doing this for many days, the politician will end up spending time on each island proportional to the population of each island - in other words, estimating the distribution of island populations correctly. How a simple comparison of only two states at a time can lead to accurate estimation of a probability density is the topic of the next few lectures.
In [3]:
def make_islands(n, low=10, high=101): islands = np.random.randint(low, high, n+2) islands[0] = 0 islands[-1] = 0 return islands
In [4]:
def hop(islands, start=1, niter=1000): pos = start pop = islands[pos] thetas = np.zeros(niter+1, dtype='int') thetas[0] = pos for i in range(niter): # generate sample from proposal distribution k = np.random.choice([-1, 1], 1) next_pos = pos + k # evaluate unnormalized target distribution at proposed position next_pop = islands[next_pos] # calculate acceptance probability p = min(1, next_pop/pop) # use uniform random to decide accept/reject proposal if np.random.random() p: pos = next_pos pop = next_pop thetas[i+1] = pos return thetas
In [5]:
islands = make_islands(10) thetas = hop(islands, start=1, niter=10000)
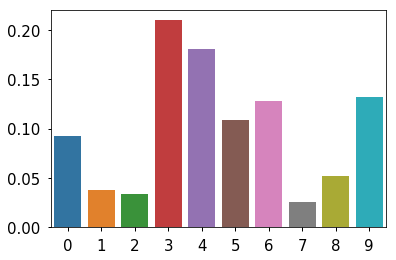
True population proportions¶
In [6]:
data = islands[1:-1] data = data/data.sum() sns.barplot(x=np.arange(len(data)), y=data) pass
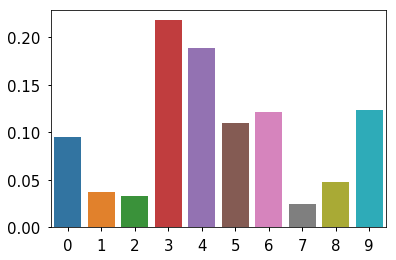
Estimated population proportions¶
In [7]:
data = np.bincount(thetas)[1:] data = data/data.sum() sns.barplot(x=np.arange(len(data)), y=data) pass
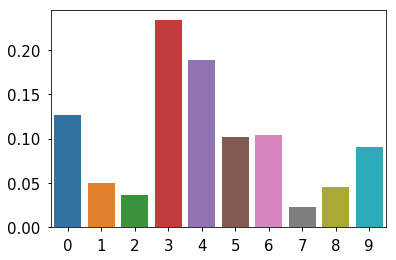
Generic Metropolis scheme¶
In [8]:
def metroplis(start, target, proposal, niter, nburn=0): current = start post = [current] for i in range(niter): proposed = proposal(current) p = min(target(proposed)/target(current), 1) if np.random.random() p: current = proposed post.append(current) return post[nburn:]
Apply to island hooper¶
In [9]:
target = lambda x: islands[x] proposal = lambda x: x + np.random.choice([-1, 1]) post = metroplis(1, target, proposal, 2000) data = np.bincount(post)[1:] data = data/data.sum() sns.barplot(x=np.arange(len(data)), y=data) pass
Bayesian Data Analysis¶
The fundamental objective of Bayesian data analysis is to determine the posterior distribution
\[p(\theta \ | \ X) = \fracwhere the denominator is
\[p(X) = \int d\theta^* p(X \ | \ \theta^*) p(\theta^*)\]- \(p(X \ | \ \theta)\) is the likelihood,
- \(p(\theta)\) is the prior and
- \(p(X)\) is a normalizing constant also known as the evidence or marginal likelihood
The computational issue is the difficulty of evaluating the integral in the denominator. There are many ways to address this difficulty, including:
- In cases with conjugate priors (with conjugate priors, the posterior has the same distribution family as the prior), we can get closed form solutions
- We can use numerical integration
- We can approximate the functions used to calculate the posterior with simpler functions and show that the resulting approximate posterior is “close” to true posterior (variational Bayes)
- We can use Monte Carlo methods, of which the most important is Markov Chain Monte Carlo (MCMC). In simple Monte Carlo inegration, we want to estimate the integral \(f(x) \, p(x) dx\) . Wtih Bayesian models, the distribution \(p(x)\) in the integral is the posterior
will not be independent unlike simple Monte Carlo integration, but this is OK as we can compensate for the auto-correlation by drawing a larger number of samples.
Motivating example¶
We will use the toy example of estimating the bias of a coin given a sample consisting of \(n\) tosses to illustrate a few of the approaches.
Analytical solution¶
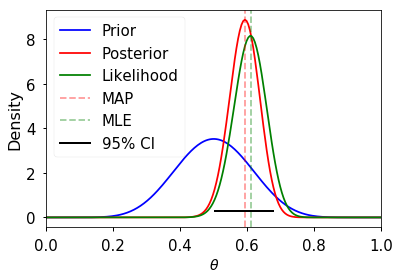
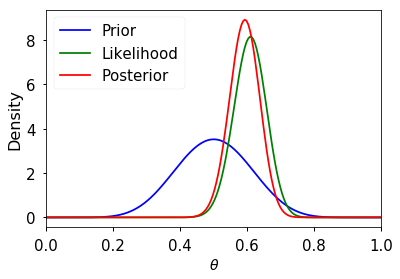
If we use a beta distribution as the prior, then the posterior distribution has a closed form solution. This is shown in the example below. Some general points:
- We need to choose a prior distribution family (i.e. the beta here) as well as its parameters (here a=10, b=10)
- The prior distribution may be relatively uninformative (i.e. more flat) or informative (i.e. more peaked)
- As the amount of data becomes large, the posterior approximates the MLE
- An informative prior takes more data to shift than an uninformative one
In [10]:
import scipy.stats as stats
In [11]:
n = 100 h = 61 p = h/n rv = stats.binom(n, p) mu = rv.mean() a, b = 10, 10 prior = stats.beta(a, b) post = stats.beta(h+a, n-h+b) ci = post.interval(0.95) thetas = np.linspace(0, 1, 200) plt.plot(thetas, prior.pdf(thetas), label='Prior', c='blue') plt.plot(thetas, post.pdf(thetas), label='Posterior', c='red') plt.plot(thetas, n*stats.binom(n, thetas).pmf(h), label='Likelihood', c='green') plt.axvline((h+a-1)/(n+a+b-2), c='red', linestyle='dashed', alpha=0.4, label='MAP') plt.axvline(mu/n, c='green', linestyle='dashed', alpha=0.4, label='MLE') plt.xlim([0, 1]) plt.axhline(0.3, ci[0], ci[1], c='black', linewidth=2, label='95% CI'); plt.xlabel(r'$\theta$', fontsize=14) plt.ylabel('Density', fontsize=16) plt.legend(loc='upper left') pass
Numerical integration¶
One simple way of numerical integration is to estimate the values on a grid of values for \(\theta\) . To calculate the posterior, we find the prior and the likelihood for each value of \(\theta\) , and for the marginal likelihood, we replace the integral with the equivalent sum
\[p(X) = \sum_ p(X | \theta^*) p(\theta^*)\]One advantage of this is that the prior does not have to be conjugate (although the example below uses the same beta prior for ease of comparison), and so we are not restricted in our choice of an appropriate prior distribution. For example, the prior can be a mixture distribution or estimated empirically from data. The disadvantage, of course, is that this is computationally very expensive when we need to estimate multiple parameters, since the number of grid points grows as \(\mathcal(n^d)\) , where \(n\) defines the grid resolution and \(d\) is the size of \(\theta\) .
In [12]:
thetas = np.linspace(0, 1, 200) prior = stats.beta(a, b) post = prior.pdf(thetas) * stats.binom(n, thetas).pmf(h) # Normalzie so volume is 1 post /= (post.sum() / len(thetas)) plt.plot(thetas, prior.pdf(thetas), label='Prior', c='blue') plt.plot(thetas, n*stats.binom(n, thetas).pmf(h), label='Likelihood', c='green') plt.plot(thetas, post, label='Posterior', c='red') plt.xlim([0, 1]) plt.xlabel(r'$\theta$', fontsize=14) plt.ylabel('Density', fontsize=16) plt.legend() pass
Markov Chain Monte Carlo (MCMC)¶
This lecture will only cover the basic ideas of MCMC and the 3 common variants - Metroplis, Metropolis-Hastings and Gibbs sampling. All code will be built from the ground up to illustrate what is involved in fitting an MCMC model, but only toy examples will be shown since the goal is conceptual understanding. More realistic computational examples will be shown in coming lectures using the pymc3 and pystan packages.
In Bayesian statistics, we want to estimate the posterior distribution, but this is often intractable due to the high-dimensional integral in the denominator (marginal likelihood). A few other ideas we have encountered that are also relevant here are Monte Carlo integration with independent samples and the use of proposal distributions (e.g. rejection and importance sampling). As we have seen from the Monte Carlo integration lectures, we can approximate the posterior \(p(\theta | X)\) if we can somehow draw many samples that come from the posterior distribution. With vanilla Monte Carlo integration, we need the samples to be independent draws from the posterior distribution, which is a problem if we do not actually know what the posterior distribution is (because we cannot integrate the marginal likelihood).
With MCMC, we draw samples from a (simple) proposal distribution so that each draw depends only on the state of the previous draw (i.e. the samples form a Markov chain). Under certain conditions, the Markov chain will have a unique stationary distribution. In addition, not all samples are used - instead we set up acceptance criteria for each draw based on comparing successive states with respect to a target distribution that ensure that the stationary distribution is the posterior distribution of interest. The nice thing is that this target distribution only needs to be proportional to the posterior distribution, which means we don’t need to evaluate the potentially intractable marginal likelihood, which is just a normalizing constant. We can find such a target distribution easily, since posterior \(\propto\) likelihood \(\times\) prior . After some time, the Markov chain of accepted draws will converge to the stationary distribution, and we can use those samples as (correlated) draws from the posterior distribution, and find functions of the posterior distribution in the same way as for vanilla Monte Carlo integration.
There are several flavors of MCMC, but the simplest to understand is the Metropolis-Hastings random walk algorithm, and we will start there.
Metropolis-Hastings random walk algorithm for estimating the bias of a coin¶
To carry out the Metropolis-Hastings algorithm, we need to draw random samples from the following distributions
- the standard uniform distribution
- a proposal distribution \(p(x)\) that we choose to be \(\mathcal(0, \sigma)\)
- the target distribution \(g(x)\) which is proportional to the posterior probability
Given an initial guess for \(\theta\) with positive probability of being drawn, the Metropolis-Hastings algorithm proceeds as follows
- Choose a new proposed value ( \(\theta_p\) ) such that \(\theta_p = \theta + \Delta\theta\) where \(\Delta \theta \sim \mathcal(0, \sigma)\)
- Caluculate the ratio
where \(g\) is the posterior probability.
- If the proposal distribution is not symmetrical, we need to weight the acceptance probability to maintain detailed balance (reversibility) of the stationary distribution, and instead calculate
Since we are taking ratios, the denominator cancels any distribution proportional to \(g\) will also work - so we can use
\[\rho = \frac- If \(\rho \ge 1\) , then set \(\theta = \theta_p\)
- If \(\rho \lt 1\) , then set \(\theta = \theta_p\) with probability \(\rho\) , otherwise set \(\theta = \theta\) (this is where we use the standard uniform distribution)
- Repeat the earlier steps
After some number of iterations \(k\) , the samples \(\theta_, \theta_, \dots\) will be samples from the posterior distributions. Here are initial concepts to help your intuition about why this is so:
- We accept a proposed move to \(\theta_\) whenever the density of the (unnormalized) target distribution at \(\theta_\) is larger than the value of \(\theta_k\) - so \(\theta\) will more often be found in places where the target distribution is denser
- If this was all we accepted, \(\theta\) would get stuck at a local mode of the target distribution, so we also accept occasional moves to lower density regions - it turns out that the correct probability of doing so is given by the ratio \(\rho\)
- The acceptance criteria only looks at ratios of the target distribution, so the denominator cancels out and does not matter - that is why we only need samples from a distribution proportional to the posterior distribution
- So, \(\theta\) will be expected to bounce around in such a way that its spends its time in places proportional to the density of the posterior distribution - that is, \(\theta\) is a draw from the posterior distribution.
Different proposal distributions can be used for Metropolis-Hastings:
- The independence sampler uses a proposal distribution that is independent of the current value of \(\theta\) . In this case the proposal distribution needs to be similar to the posterior distribution for efficiency, while ensuring that the acceptance ratio is bounded in the tail region of the posterior.
- The random walk sampler (used in this example) takes a random step centered at the current value of \(\theta\) - efficiency is a trade-off between small step size with high probability of acceptance and large step sizes with low probability of acceptance. Note (picture will be sketched in class) that the random walk may take a long time to traverse narrow regions of the probability distribution. Changing the step size (e.g. scaling \(\Sigma\) for a multivariate normal proposal distribution) so that a target proportion of proposals are accepted is known as tuning.
- Much research is being conducted on different proposal distributions for efficient sampling of the posterior distribution.
We will first see a numerical example and then try to understand why it works.
In [13]:
def target(lik, prior, n, h, theta): if theta 0 or theta > 1: return 0 else: return lik(n, theta).pmf(h)*prior.pdf(theta) n = 100 h = 61 a = 10 b = 10 lik = stats.binom prior = stats.beta(a, b) sigma = 0.3 naccept = 0 theta = 0.1 niters = 10000 samples = np.zeros(niters+1) samples[0] = theta for i in range(niters): theta_p = theta + stats.norm(0, sigma).rvs() rho = min(1, target(lik, prior, n, h, theta_p)/target(lik, prior, n, h, theta )) u = np.random.uniform() if u rho: naccept += 1 theta = theta_p samples[i+1] = theta nmcmc = len(samples)//2 print("Efficiency = ", naccept/niters)
Efficiency = 0.1861
